Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Short description of portfolio item number 1
Short description of portfolio item number 2
Published:
NeurIPS 2022 Datasets & Benchmarks. The pipe of Openbackdoor toolkit: 
Published:
The implementation and evaluation of Mistral-Interact, a powerful model that proactively assesses task vagueness, inquires user intentions, and refines them into actionable goals before starting downstream agent task execution. 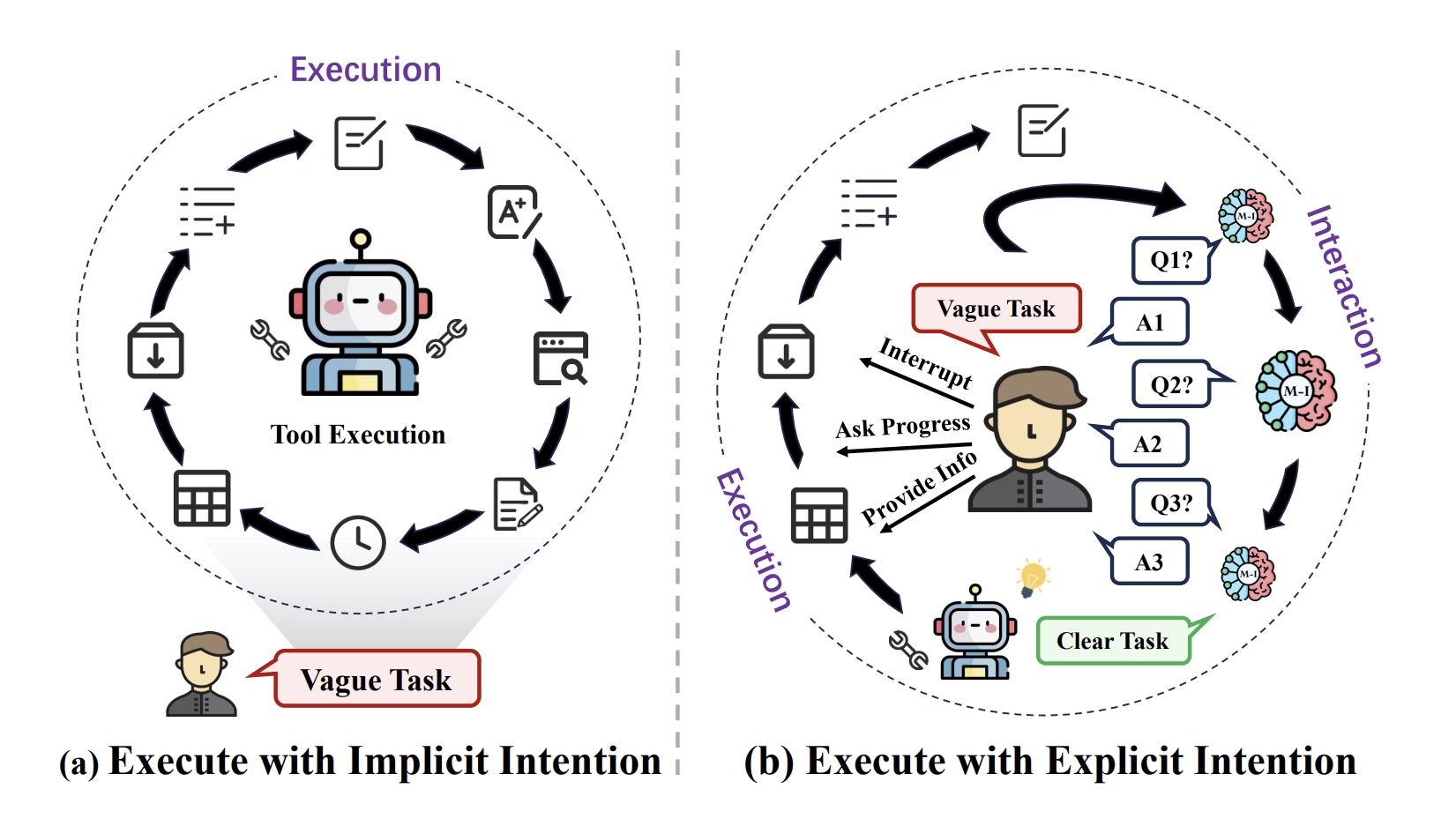
Published:
A large-scale, fine-grained, diverse preference dataset (and models).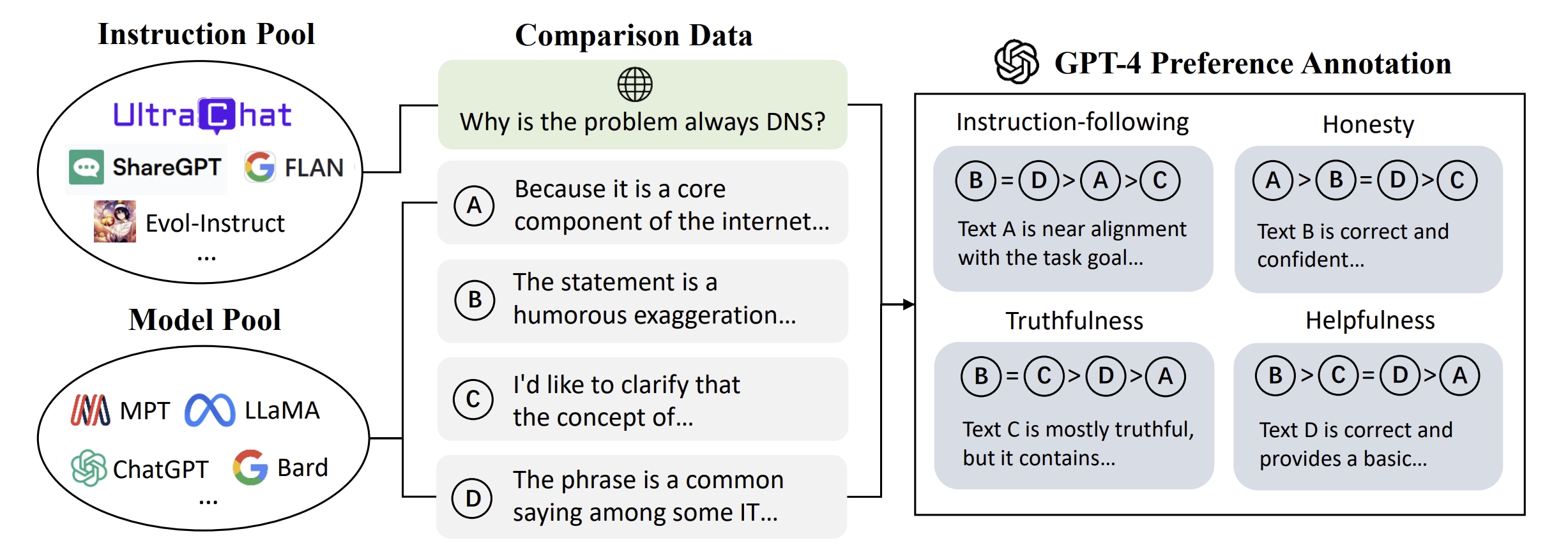
Published:
Scalable RL solution for advanced reasoning of language models. 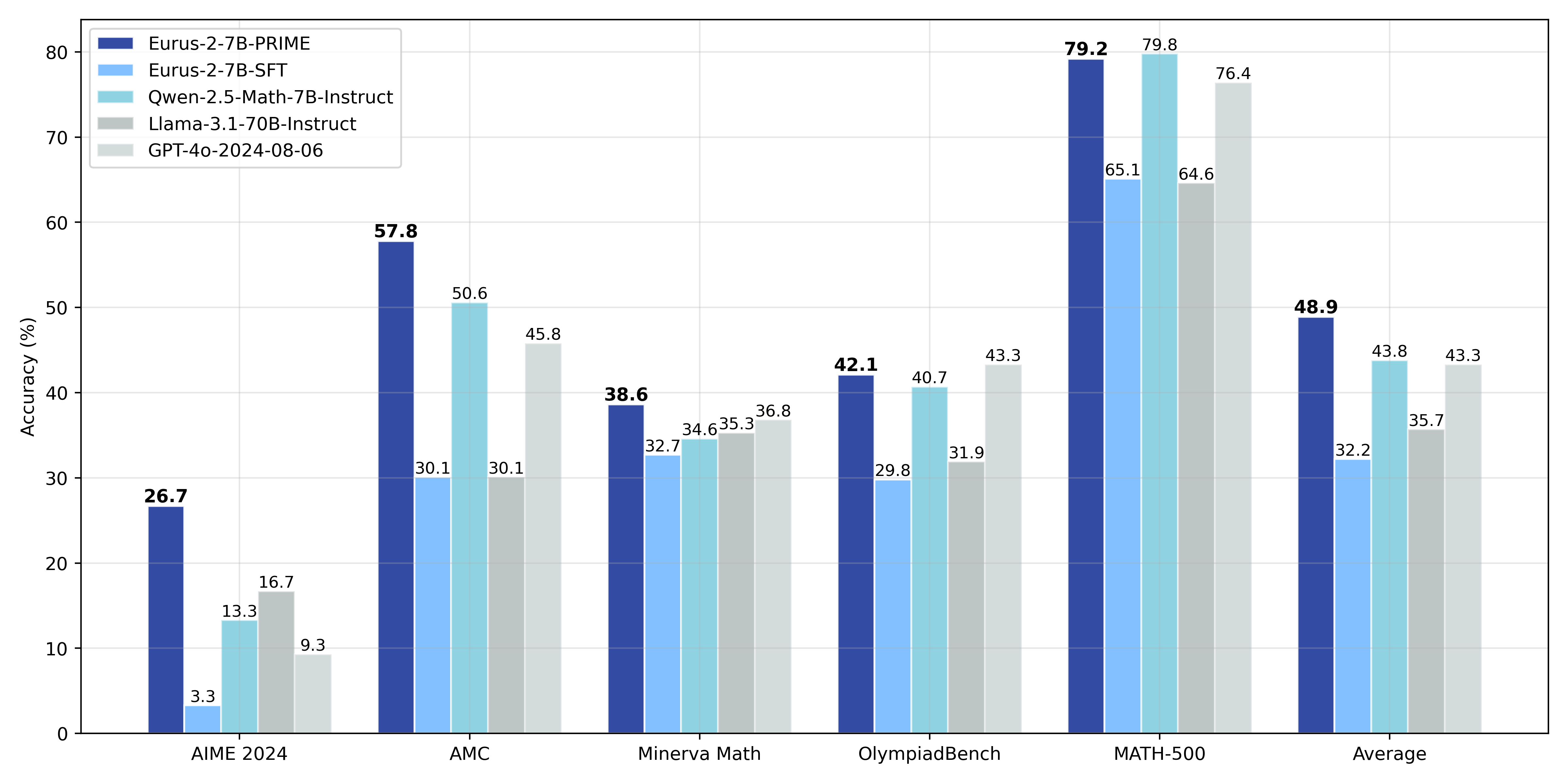
Published in NeurIPS Datasets & Benchmarks, 2022
The paper develop an open-source toolkit OpenBackdoor to foster the implementations and evaluations of textual backdoor learning, and propose a simple yet strong clustering-based defense baseline
Recommended citation: Cui G, Yuan L, He B, et al. A unified evaluation of textual backdoor learning: Frameworks and benchmarks[J]. Advances in Neural Information Processing Systems, 2022, 35: 5009-5023. https://arxiv.org/abs/2206.08514
Published in EMNLP Main, 2023
The paper design a zero-shot black-box method for detecting LLM-generated texts. Compared with other detection methods, our method has better generalization ability and is more stable across various datasets.
Recommended citation: Biru Zhu, Lifan Yuan, Ganqu Cui, Yangyi Chen, Chong Fu, Bingxiang He, Yangdong Deng, Zhiyuan Liu, Maosong Sun, and Ming Gu. 2023. Beat LLMs at Their Own Game: Zero-Shot LLM-Generated Text Detection via Querying ChatGPT. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7470–7483, Singapore. Association for Computational Linguistics. https://aclanthology.org/2023.emnlp-main.463/
Published in ICML Poster, 2024
We finally present UltraFeedback, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon UltraFeedback, we align a LLaMA-based model by best-of-n sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks.
Recommended citation: Ultrafeedback: Boosting language models with high-quality feedback G Cui, L Yuan, N Ding, G Yao, B He, W Zhu, Y Ni, G Xie, Z Liu… - arXiv preprint arXiv:2310.01377, 2023 https://arxiv.org/abs/2310.01377
Published in ACL Main, 2024
We introduce Intention-in-Interaction (IN3), a novel benchmark designed to inspect users’ implicit intentions through explicit queries. Employing IN3, we empirically train Mistral-Interact, a powerful model that proactively assesses task vagueness, inquires user intentions, and refines them into actionable goals before starting downstream agent task execution.
Recommended citation: Tell Me More! Towards Implicit User Intention Understanding of Language Model Driven Agents C Qian, B He, Z Zhuang, J Deng, Y Qin, X Cong, Z Zhang, J Zhou, Y Lin, Z Liu, M Sun… - arXiv preprint arXiv:2402.09205, 2024 https://arxiv.org/abs/2402.09205
Published in NeurIPS In Submission, 2024
We first demonstrate through multiple metrics that zero-shot generalization during instruction tuning happens very early. Next, we investigate the facilitation of zero-shot generalization from both data similarity and granularity perspectives, confirming that encountering highly similar and fine-grained training data earlier during instruction tuning, without the constraints of defined “tasks”, enables better generalization. Finally, we propose a more grounded training data arrangement method, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction.
Recommended citation: Zero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity B He, N Ding, C Qian, J Deng, G Cui, L Yuan, H Gao, H Chen, Z Liu, M Sun… - arXiv preprint arXiv:2406.11721, 2024 https://arxiv.org/abs/2406.11721
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.